Python Tutorials

This is my ongoing list of Python Tutorials. I'm currently merging my various Python Tutorials into one cohesive list below as a way to reduce the amount of posts all over my site. Thank you for your patience and please feel free to drop me a Tweet if you have any comments or questions.
Disqus Comment Migration Hack (code)
I'm working on syncing up my post comments on Disqus again. Since I moved to Hugo, I had to update my post slugs to generate into different channels. I split the majority of posts in /blog/, /tutorials/, and /reviews/ now. There's a lot of great comments in many of my popular posts but because Disqus has this weird way of mapping the URLs, I turned off Disqus until I worked on a solution to syncing them from /my-old-slug to /blog/my-new-slug/.
In a nutshell, Disqus allows you to download a CSV file of all the links it has of your site. That list is where Disqus knows it has comments and if your new URL schema is different, well then Disqus doesn't know how to sync up the comments to your new slug schema.
Once you have that CSV, Disqus wants you to add another column with the updated URL. Updating the slugs is pretty easy to do if you less than 20 or so posts but if you have a site like mine with over 1,800 posts, it becomes unwieldy to manually type everything in. If only I could use Python to extract the current URLs from my RSS feed, then copy and paste them into the Disqus CSV file, upload, and wait 24 hours.
That's almost exactly what I did this morning. I used Python to extract the current slugs from my feed and then paste them into the CSV file. I uploaded the CSV file and if all goes well I should see old comments syncing back up to the posts over the next 24 hours.
Once the comments are properly migrated I'm ditching Disqus for another system altogether. Disqus is a performance hog and I'm looking to use Commento instead. Commento has a Disqus import feature but slugs need to be properly synced first, so this Disqus update is just phase 1 of a larger migration of my comments for this site.
For this tutorial, I'm just posting a short python script that you can use to extract your current post slugs/links and write them to a text file. If you're using Disqus and need to remap the old URLs, just grab the links in the text file and paste them into the CSV file for upload.
import feedparser
blog = 'https://www.neuralmarkettrends.com/blog/index.xml'
tutorials = 'https://www.neuralmarkettrends.com/tutorials/index.xml'
b = feedparser.parse(blog)
t = feedparser.parse(tutorials)
bfeedlen = len(b['entries'])
tfeedlen = len(t['entries'])
blogfile = open('blog.txt','w')
for i in range(0, bfeedlen):
blogfile.write((b['entries'][i]['link'])+'\n')
else:
blogfile.close()
print ("Error or End of the Line")
tutorialfile = open('tutorial.txt','w')
for i in range(0, tfeedlen):
tutorialfile.write((t['entries'][i]['link'])+'\n')
else:
tutorialfile.close()
print ("Error or End of the Line")
Process Files to Folders for Hugo using Python (code)
I've been using Hugo for my CMS and it's been a dream. However there's one small problem, my content is not structured in the preferred Hugo way. Right now I have a set of single folders called blog, tutorials, and reviews. Then I have a bunch of single markdown files in there like below:

{{< img src="existingfolder.png" alt="Existing Markdown Files" >}}
To have Hugo do all kinds of image and file processing, I need to change the structure a post folder name and the post into an index.md file. Then I can place all the 'page resources' such as images and other format files for Hugo to process upon build. The preferred content structure is below:
- content
|- blog/
|- 2018-08-04-The Art of the Journal
- index.md
|- 2018-08-12-Making-Stock-from-bones
- index.md
|- 2018-08-16-Current-Status
- index.md
So how did I process 2000 files into folders and rename the markdown file automatically? I did it with Python. I wrote a simple script to take markdown files, read their name, create a folder named as the markdown file (without the .md extension) and save the renamed index.md file to the same directory.
I chose Python because I started doing this by hand and said, 'this is stupid to do by hand', and I don't know GoLang well enough to do this in the Hugo environment. So I choose my default automation language, Python to do it. It took me about 30 minutes to get this to work right and now I'll share it with you.
Python Code
The very first thing we do is initialize two libraries, os and glob. Then you create a python list and load in all markdown files in your folder. For a check, I just print them out to make sure it got them.
Note, I had copied the markdown files to a directory called ./content/input but you can change that any directory you like.
import os
from glob import glob
files_list = []
files_list = glob(os.path.join('./content/input/', '*.md'))
#check to see if files_list is being populated
print (files_list)
The very next thing is just a simple loop where we do three operations. First, we strip the filename (myHugoPost.md) into two parts, the name of the markdown file (myHugoPost) and the markdown extension (.md), we then discard the markdown extension.
Once I have the name of the file my second operation is simply to create a new folder with that name.
The third and last operation is to take that original myHugoPost.md file, rename it to index.md, and save it under the myHugoPost folder.
Done.
for a_file in sorted(files_list):
try:
#strip first part of filename
fname = os.path.splitext(a_file)[0]
print (fname)
#make new directories in /tmp folder
os.makedirs('./output/'+fname)
#rename and save file to new directory
#kinda hacky, can make more elegant
os.rename(a_file, './output/'+fname+'/index.md')
print ('Made directory & saved index.md file to: ', fname)
except OSError:
#this is very hacky, need to print out what files were missed
pass
The final Python script looks like this:
import os
from glob import glob
files_list = []
files_list = glob(os.path.join('./content/input/', '*.md'))
#check to see if files_list is being populated
print (files_list)
for a_file in sorted(files_list):
try:
#strip first part of filename
fname = os.path.splitext(a_file)[0]
print (fname)
#make new directories in /tmp folder
os.makedirs('./output/'+fname)
#rename and save file to new directory
#kinda hacky, can make more elegant
os.rename(a_file, './output/'+fname+'/index.md')
print ('Made directory & saved index.md file to: ', fname)
except OSError:
pass
This script is very hacky and there are some things I should improve upon the next time I run it (if at all). I want to handle the paths and folders better instead of hardcoding that in. Second, I need to do better error handling, passing the error is a big problem because if some files did cause an error, I wouldn't know what they were. So better error handling and logging are what I need to write in here.
Otherwise, then that, feel free to use this script to process your files into folders if you're transitioning from some other CMS to Hugo.
H2O AutoML with Streamlit
Streamlit has to be one of my favorite new libraries out there and I experiment with it when I have time. For fun I wanted to see how easy it would be to build a simple UI with Streamlit and wrap H2O-3's AutoML into it, to build your own AutoML tool. In about 100 lines of code I was able to make a simple website that lets users upload a training data set and a scoring data set.
It runs H2O-3 AutoML for a binary type of problem and then gives you the predicted results. It's a simple POC (Proof of Concept) but it was fun nonetheless because Streamlit is so lightweight to use.
{{< img src="streamlit-h2o-automl-1.png" alt="Streamlit and H2O-3's AutoML" >}}
First initialize the required Python libraries
This is pretty straight forward, you'll need Streamlit, Pandas, H2O, and time.
import streamlit as st
#import numpy as np
import pandas as pd
import time
import h2o
from h2o.automl import H2OAutoML
Set some environmental variables
I decided to keep this code focused on binary class problems, but with H2O-3's AutoML you can extend it to regression type problems too. That would be for another tutorial.
All I did was set the seed number, put the max folds for Cross Validation, the early stopping metric, and the maximum models to train. If you've ever used AutoML from H2O, it's really nice and powerful.
#Set some variables here (use this area to set up parameters for AutoML and datasets)
seed = 1234
nfolds = 5
stopping_metric = 'AUC'
max_models = 10
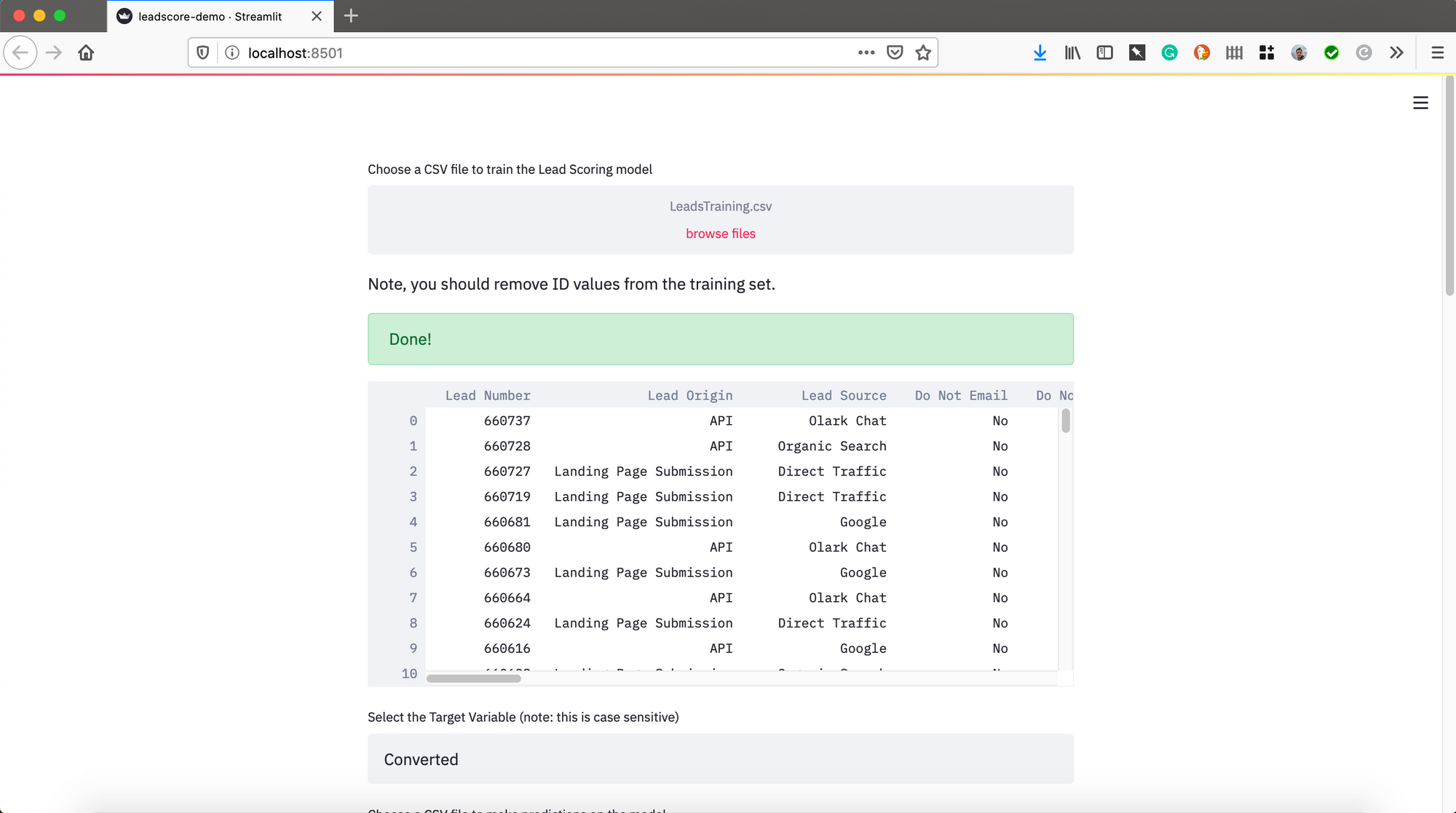
Uploading a Training and Scoring Dataset
{{< img src="streamlit-h2o-automl-2.png" alt="Streamlit and H2O-3's AutoML" >}}
Here I just read through the Streamlit documentation to figure out how to do this. I loaded up two datasets, one for training and one for scoring. I assigned them to pandas dataframes to manipulated them and then sent them an H2O dataframe for modeling and predicting. Note, I added a random sample of the scoring data to make this go faster, you may comment that out if you like.
ploaded_file = st.file_uploader("Choose a CSV file to train the Lead Scoring model", type="csv")
st.write('Note, you should remove ID values from the training set.')
if uploaded_file is not None:
data = pd.read_csv(uploaded_file)
with st.spinner('Wait for it...'):
time.sleep(5)
st.success('Done!')
st.write(data)
target = st.text_input('Select the Target Variable (note: this is case sensitive)', 'Converted')
#ID = st.text_input('Select the ID column (note: this is case sensitive)', 'ID')
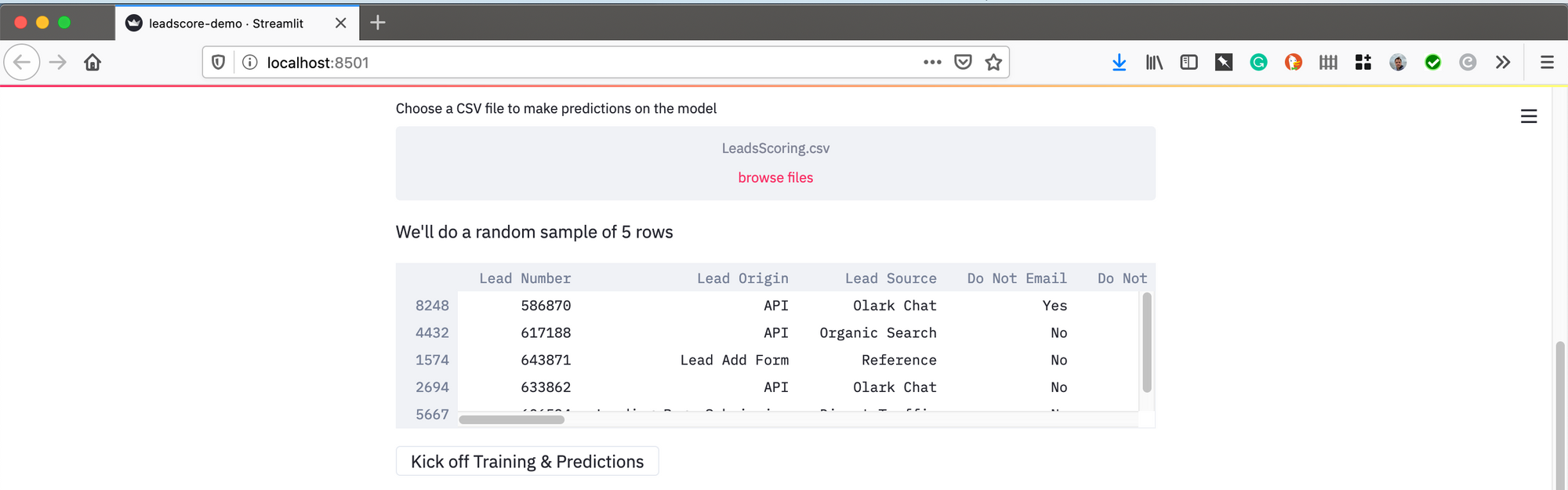
uploaded_file = st.file_uploader("Choose a CSV file to make predictions on the model", type="csv")
if uploaded_file is not None:
load = pd.read_csv(uploaded_file)
predict = load.sample(5)
st.write("We'll do a random sample of 5 rows", predict)
Kick of Training and Scoring
Now comes the fun part, the training and scoring. Streamlit let's you add buttons and all kinds of standard web things to interact with your application. I just made a 'Kick Off Training and Scoring' button that launched the H2O cluster. It loaded in the pandas dataframe, built 10 models in AutoML, and grabbed the best model based on AUC. After that I grabbed the 2nd best model for variable importance.
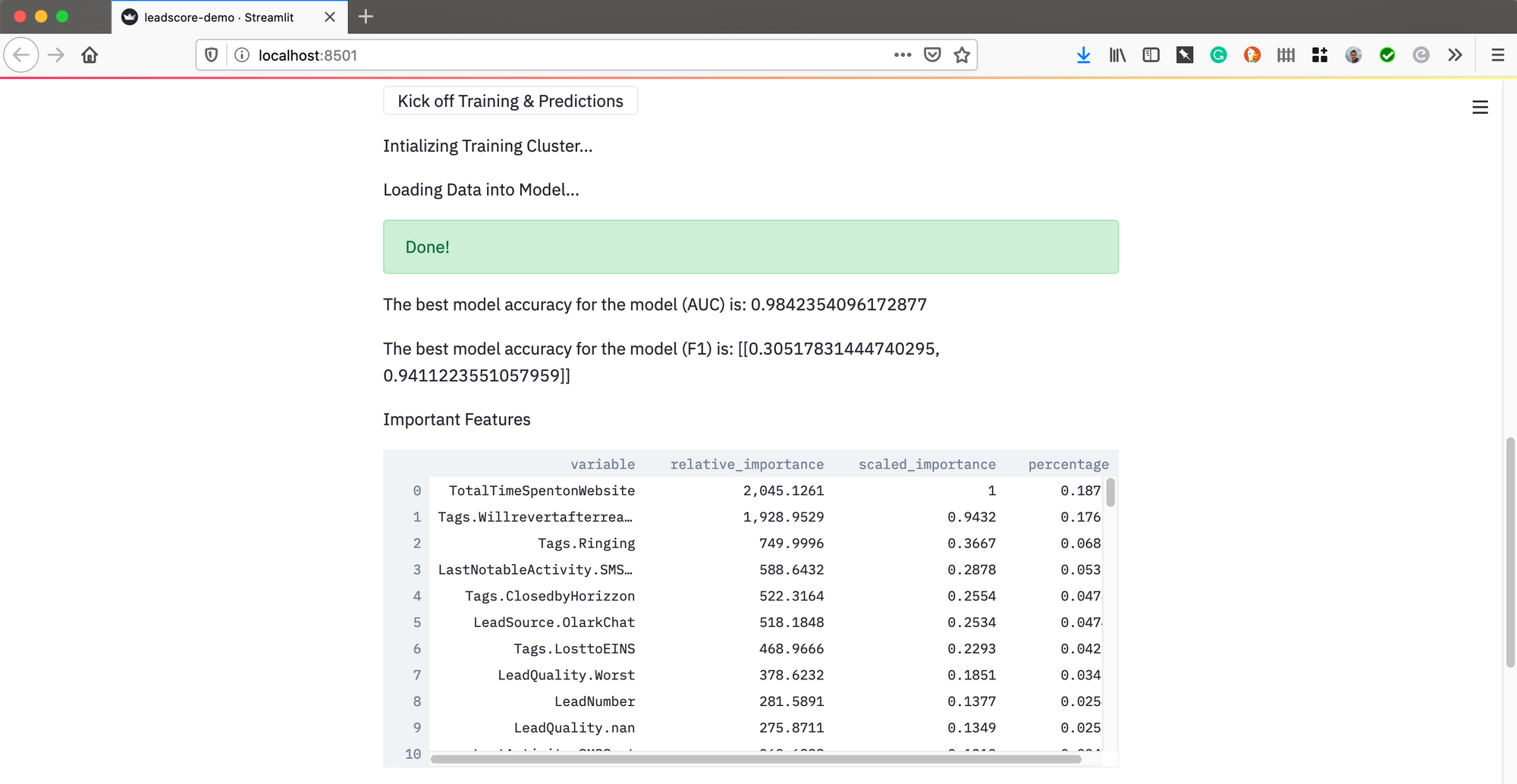
Why did I do that? There appears to be an issue with feature importance when using the top stacked ensemble model, so for this POC we just grabbed the 2nd best and lived with it.
It grabs the 2nd best model and the scores on it, displaying the results.
if st.button('Kick off Training & Predictions'):
st.write('Intializing Training Cluster...')
#Initialize H2O cluster
h2o.init()
st.write('Loading Data into Model...')
train = h2o.H2OFrame(data)
train,test= train.split_frame(ratios=[.7])
# Identify predictors and response
x = train.columns
y = target
x.remove(y)
train[y] = train[y].asfactor()
test[y] = test[y].asfactor()
# Run AutoML for 20 base models (limited to 1 hour max runtime by default)
with st.spinner('Wait for it...'):
aml = H2OAutoML(max_models=max_models, seed=seed, nfolds=nfolds, stopping_metric=stopping_metric, exclude_algos = ["StackedEnsemble", "DeepLearning", "DRF"])
aml.train(x=x, y=y, training_frame=train)
time.sleep(5)
st.success('Done!')
# View the AutoML Leaderboard
lb = aml.leaderboard
#lb.head(rows=lb.nrows)
# Get Leader Accuracy
perf_leader = aml.leader.model_performance(test).auc()
st.write("The best model accuracy for the model (AUC) is:", str(perf_leader))
perf_f1 = aml.leader.model_performance(test).F1()
st.write("The best model accuracy for the model (F1) is:", str(perf_f1))
m = h2o.get_model(lb[2,"model_id"])
FI = m.varimp(use_pandas=True)
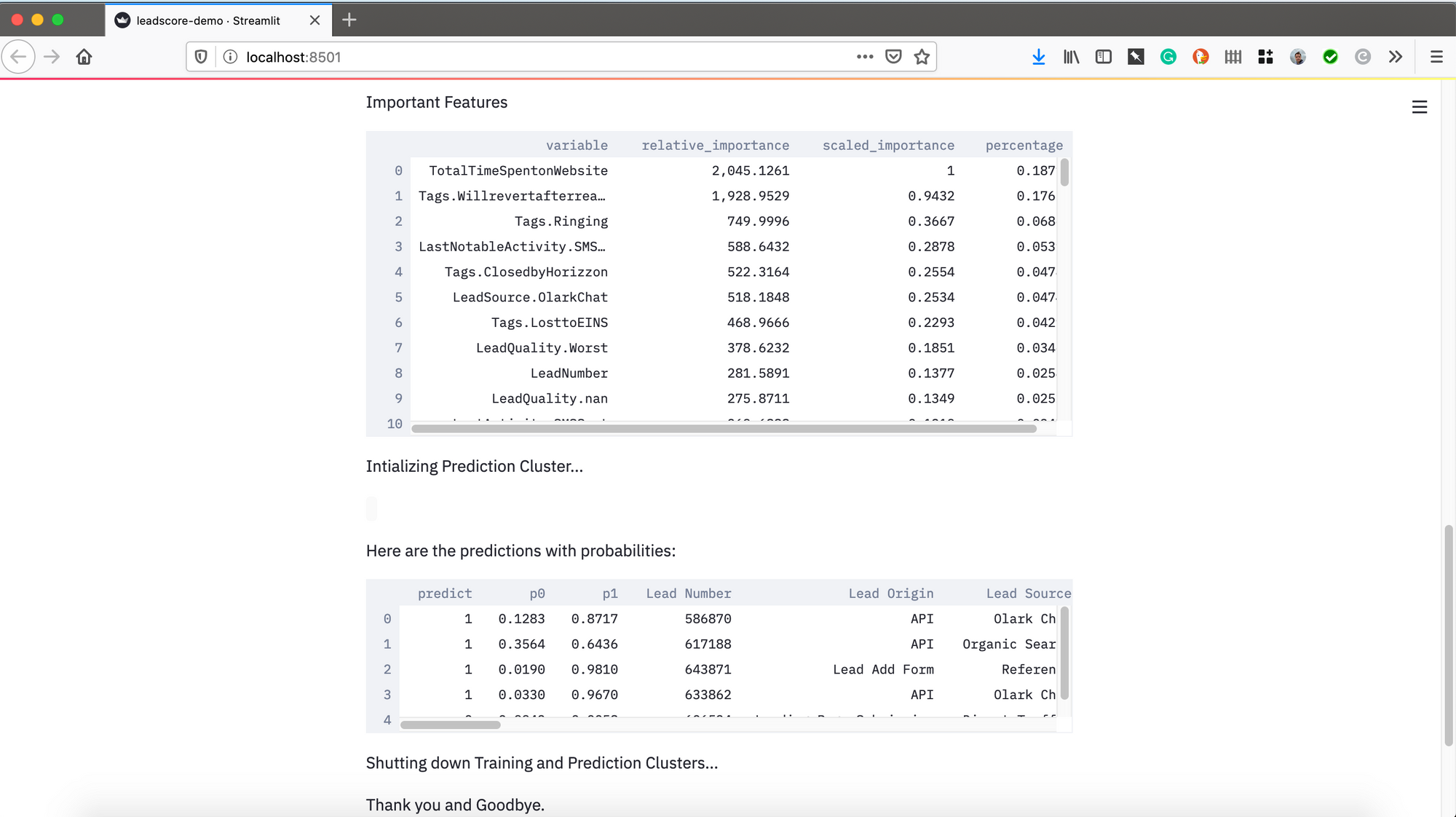
st.write("Important Features", FI)
# Get predictions
preds = aml.predict(test)
print(preds)
predict_frame = h2o.H2OFrame(predict)
preds = aml.predict(predict_frame)
st.write('Intializing Prediction Cluster...')
st.write(preds)
tmp = preds.as_data_frame()
tmp2 = predict_frame.as_data_frame()
out = pd.merge(tmp, tmp2, left_index=True, right_index=True)
st.write('Here are the predictions with probabilities:', out)
st.write('Shutting down Training and Prediction Clusters...')
h2o.cluster().shutdown()
st.write("Thank you and Goodbye.")
else:
pass
Complete Python Code
Below is the complete code.
import streamlit as st
import numpy as np
import pandas as pd
import time
import h2o
from h2o.automl import H2OAutoML
#Set some variables here (use this area to set up parameters for AutoML and datasets)
seed = 1234
nfolds = 5
stopping_metric = 'AUC'
max_models = 10
uploaded_file = st.file_uploader("Choose a CSV file to train the Lead Scoring model", type="csv")
st.write('Note, you should remove ID values from the training set.')
if uploaded_file is not None:
data = pd.read_csv(uploaded_file)
with st.spinner('Wait for it...'):
time.sleep(5)
st.success('Done!')
st.write(data)
target = st.text_input('Select the Target Variable (note: this is case sensitive)', 'Converted')
#ID = st.text_input('Select the ID column (note: this is case sensitive)', 'ID')
uploaded_file = st.file_uploader("Choose a CSV file to make predictions on the model", type="csv")
if uploaded_file is not None:
load = pd.read_csv(uploaded_file)
predict = load.sample(5)
st.write("We'll do a random sample of 5 rows", predict)
if st.button('Kick off Training & Predictions'):
st.write('Intializing Training Cluster...')
#Initialize H2O cluster
h2o.init()
st.write('Loading Data into Model...')
train = h2o.H2OFrame(data)
train,test= train.split_frame(ratios=[.7])
# Identify predictors and response
x = train.columns
y = target
x.remove(y)
train[y] = train[y].asfactor()
test[y] = test[y].asfactor()
# Run AutoML for 20 base models (limited to 1 hour max runtime by default)
with st.spinner('Wait for it...'):
aml = H2OAutoML(max_models=max_models, seed=seed, nfolds=nfolds, stopping_metric=stopping_metric, exclude_algos = ["StackedEnsemble", "DeepLearning", "DRF"])
aml.train(x=x, y=y, training_frame=train)
time.sleep(5)
st.success('Done!')
# View the AutoML Leaderboard
lb = aml.leaderboard
#lb.head(rows=lb.nrows)
# Get Leader Accuracy
perf_leader = aml.leader.model_performance(test).auc()
st.write("The best model accuracy for the model (AUC) is:", str(perf_leader))
perf_f1 = aml.leader.model_performance(test).F1()
st.write("The best model accuracy for the model (F1) is:", str(perf_f1))
m = h2o.get_model(lb[2,"model_id"])
FI = m.varimp(use_pandas=True)
st.write("Important Features", FI)
# Get predictions
preds = aml.predict(test)
print(preds)
predict_frame = h2o.H2OFrame(predict)
preds = aml.predict(predict_frame)
st.write('Intializing Prediction Cluster...')
st.write(preds)
tmp = preds.as_data_frame()
tmp2 = predict_frame.as_data_frame()
out = pd.merge(tmp, tmp2, left_index=True, right_index=True)
st.write('Here are the predictions with probabilities:', out)
st.write('Shutting down Training and Prediction Clusters...')
h2o.cluster().shutdown()
st.write("Thank you and Goodbye.")
else:
pass
I really simplified this and even if you got an AUC of 0.99 I would be very suspect. The dataset I experimented with was a lead scoring data set from Kaggle that had 2 leaking features and I dropped some columns because they were causing the AutoML to crash, so there's a lot of stuff that I would need to build in the code for error checking. On top of all this, I didn't do ANY feature engineering whatsoever so this model could use work. Plus, I should've added some Matplotlib or Plotly visualizations.
Still, this was a fun exercise indeed.
{{< img src="streamlit-h2o-automl-4.png" alt="Streamlit and H2O-3's AutoML" >}}
Build a Simple Candlestick Chart in Streamlit with Plotly
A few months ago I learned about a new open-source and python based dashboard project called Streamlit.io. It looked pretty nice and I finally took some time to test it out. The result? It's super easy to whip up a dashboard in minutes! Below is an interactive candlestick chart using Streamlit and Plotly, whose code I borrowed from my Candlesticks in Plotly post and 'riffed' on it.
How to Use
Using this script is pretty easy, all you need to do is install Streamlit and Plotly via the standard pip install methods. You can put them into a virtual environment or not.
Then grab the script below and save it to a .py file. I called mine chart.py and spun it up by doing 'streamlit run chart.py'
After a few seconds, you should see this image.
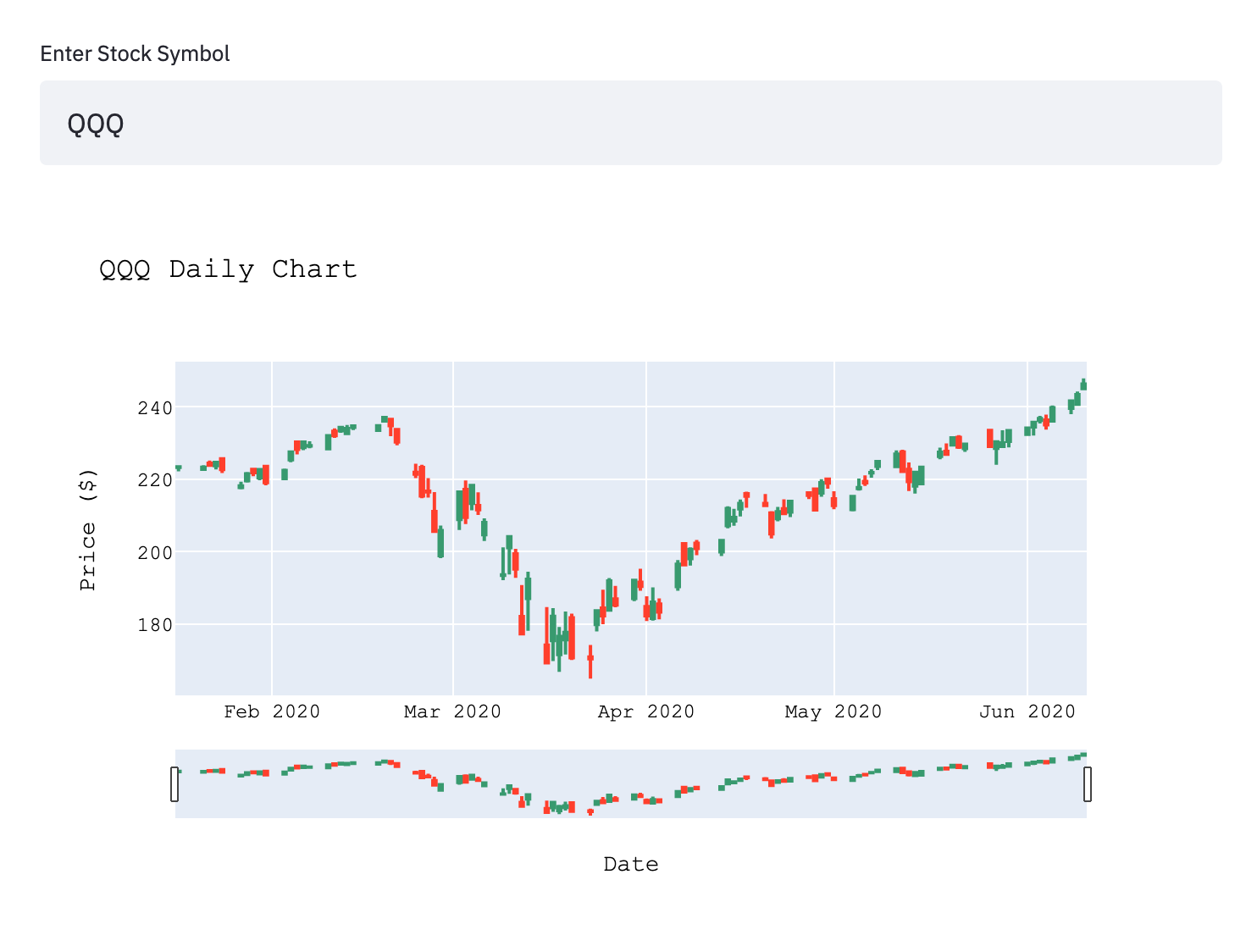
You can build new stock charts on the 'fly' by entering a new stock symbol and pressing enter. This symbol will be passed to the code and a new query to Alphavantage will be sent and returned. Note, you will need to get an Alphavantage API key and paste it where the 'XXXXXXXXXXXX' is in "apikey": "XXXXXXXXXXXX" }.
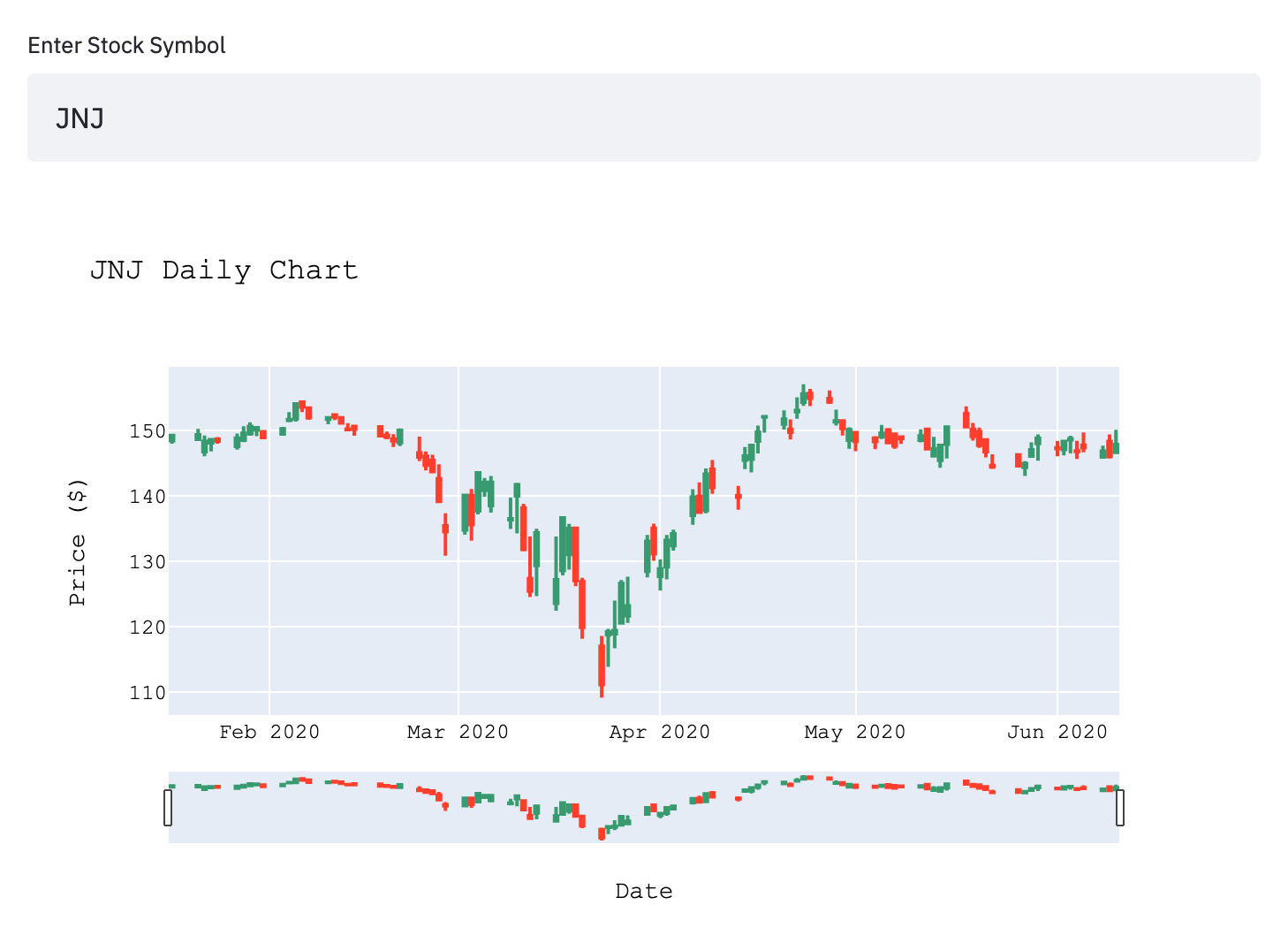
Right now this simple and interactive dashboard is running on my local machine but I plan on deploying it to its own instance on AWS.
Python Code
import streamlit as st
import plotly.figure_factory as ff
import plotly.graph_objects as go
import numpy as np
import pandas as pd
import requests
# Set sample stock symbol to instrument variable
symbol = st.text_input('Enter Stock Symbol', 'QQQ')
API_URL = "https://www.alphavantage.co/query"
data = { "function": "TIME_SERIES_DAILY",
"symbol": symbol,
"outputsize" : "compact",
"datatype": "json",
"apikey": "XXXXXXXXXXXX" } #ENTER YOUR ALPHAVANTAGE KEY HERE
#https://www.alphavantage.co/query/
response = requests.get(API_URL, data).json()
data = pd.DataFrame.from_dict(response['Time Series (Daily)'], orient= 'index').sort_index(axis=1)
data = data.rename(columns={ '1. open': 'Open', '2. high': 'High', '3. low': 'Low', '4. close': 'Close', '5. volume': 'Volume'})
data = data[['Open', 'High', 'Low', 'Close', 'Volume']]
data['Date'] = data.index
fig = go.Figure(data=[go.Candlestick(x=data['Date'],
open=data['Open'],
high=data['High'],
low=data['Low'],
close=data['Close'],
name=symbol)])
fig.update_layout(
title=symbol+ ' Daily Chart',
xaxis_title="Date",
yaxis_title="Price ($)",
font=dict(
family="Courier New, monospace",
size=12,
color="black"
)
)
st.plotly_chart(fig, use_container_width=True)
Use Python to Build a BDR Salesforce Bot
The job of a BDR (Business Development Rep) is hard and stressful, but it can be very rewarding when you hit some 'hot leads'. They spend a lot of time downloading an AE's (Account Executive) account list, looking at leads, prospecting the company, and finding relevant LinkedIn connections. Searching for these relevant connections is very hard and BDR's usually do LinkedIn searches like:
"Company XYZ" and VP and Data Science
Then they get a results list from LinkedIn and look through the list and figure out who to connect too. Then they repeat the process for the next account list ad infinitum. This is a lot of manual work and I scratched my head thinking that a lot of this process can be automated!
A while ago I built a simple python script that uses a Python Salesforce API and Selenium for browser automation. I decided to use the DuckDuckGo search engine to search for LinkedIn connections instead of Google. Google seems to play games with the HTML for its result pages. It changes the link classes randomly to prevent you from scraping Google results. Oh, the irony indeed!
Here's how I did it.
Load the Python libraries
You'll need Pandas, Selenium, and Simple Salesforce libraries. You'll need to be calling the sleep function, datetime, and random. These libraries are for manipulating the Salesforce API data once you load it in. This part is pretty straight forward.
from time import sleep
import pandas as pd
from simple_salesforce import Salesforce
import pandas as pd
from pandas.io.json import json_normalize
# import web driver
from selenium import webdriver
import datetime as DT
import random
Set up your Salesforce credentials
You should read up on the Simple Salesforce API, there are a lot of great examples. What I'm doing here is setting up the variables needed to make the Salesforce connection and set up the AE's name that will be used for the account list query.
I'm also setting a today variable because I use this to append a spreadsheet before saving it.
#Set Up some Key variables
sfusername = 'your@email.com'
sfpassword = 'yourSFDCpassword'
sftoken = 'putyourSDFCtoken'
sfowner = 'the AE name you want to BDR prospect for'
today = str(DT.date.today())
Here I just pass the connection string to Salesforce API and make the connection
#Initialize Connection to SFDC
sf = Salesforce(username=sfusername, password=sfpassword, security_token=sftoken)
Run Salesforce Query and download the Account List
Once I connect to Salesforce API I write a simple query. All that I do here is I search for all the Accounts for the Account Executive. That's where the sfowner variable is used but you have to format it. So if you have an AE named Joe Sixpack, you have to use .format('Joe Sixpack') at the end of the query statement.
Now you can modify the query and I routinely do that on the FROM part to select Leads or Opportunities, but for today's example, we'll stick to only the AE's accounts.
I grab the entire data which is in JSON format, flatten it, and write it out as an XLS called 'account_list.xls'
This is handy for the BDR to review because here's where Salesforce hygiene becomes important. The Account names column (called 'Names') will be used for searching LinkedIn and if it's not correct, you'll get bad results. So this should be reviewed.
#Run Query for the AE that has Company Names in their Account
query = sf.query("SELECT Id, Account.Name FROM Account WHERE Owner.Name = '{}' ".format(sfowner))
current_accounts = pd.DataFrame(query, columns=query.keys())
current_accounts = json_normalize(current_accounts['records'])
current_accounts.to_excel('account_list.xls')
Define the Browser function
Now, this part gets interesting. We're going to use Selenium's built-in Firefox automated browser. To call it you just need to set a driver = webdriver.FireFox(). It's that simple. We then build a loop to loop over all the Company names in the current_accounts object. This is the payload you pass when you call the function firefox_browser(current_accounts).
The key thing you want to adjust and define is what the browser is going to look for. Since we want to extract the company name from the current_accounts and search LinkedIn for people associated with the company I want to connect with, your search string needs to be pretty specific. This is where DuckDuckGo's simple search syntax becomes important. You should read it and familiarize yourself with it.
For example, since we want to only search for people to connect with a specific company on LinkedIn, we can do ask the browser to go here:
https://duckduckgo.com/site:linkedin.com/in/
This narrows your search down to the LinkedIn site.
Next, we want to add the company name. You want to add a space character and then "Google", like so:
https://duckduckgo.com/site:linkedin.com/in/ "Google"
This search string would now use LinkedIn to search for people associated with the company Google. You can narrow it down to specific people with certain 'keywords' in their public profiles, like "Data Science," so the search string becomes:
https://duckduckgo.com/site:linkedin.com/in/ "Google" AND "Data Science"
That's what I do below. I also add in several delay functions because you can easily rate block yourself on DuckDuckGo.
For sake of simplicity, I just grab the first 10 results on the first page for my search string, save them to an XLS, and then loop to the next company name. Once the function has a loop over your account list, it exits. Done.
# Define the scraping process using Firefox browser automation
def firefox_browser(data):
driver = webdriver.Firefox()
for a_name in data['Name']:
driver.get('https://duckduckgo.com/site:linkedin.com/in/ "'+a_name+'" AND "VP" "Director" AND "Data Science" "Machine Learning" ')
results=driver.find_elements_by_class_name('result__a')
time = random.randint(10,35)
sleep(time)
link_list=[]
for result in results:
link_list.append(result.get_attribute('href'))
linkedin_urls = pd.DataFrame(link_list, columns = ['RawURL'])
time = random.randint(10,35)
sleep(time)
#Write results to a directory
linkedin_urls.to_excel('./'+a_name+'_'+today+ '_linkedin_scrape.xls')
print (a_name+' links scraped and saved to folder...')
sleep(time)
#terminates the application
driver.quit()
The way you call the function if you're not familiar with python, is like this:
#launch FF browser for current_accounts list.
firefox_browser(current_accounts)
YOU WILL RATE BLOCK YOURSELF unless you use this script or its derivatives wisely and humanely. Hopefully, I scared you now because I rate blocked myself on DuckDuckGo a few times and have learned a few lessons.
Here's what I learned:
- If you have more than 50 accounts, you should break up the list in smaller chunks. Don't try to process more than 50 at a time. Be a GOOD Internet citizen!
- Delay processing. I routinely put 30-minute delays between function calls and scraping to avoid problems.
- Don't run this every day. Do it once a month, if you have 50 accounts you get 50 spreadsheets with LinkedIn URLS.
The outputting spreadsheets will have URLs to people's profiles associated with the company. You will need to open them manually click them and read up on them. Then you can make the final choice whether to connect to them or not. I chose NOT to automate this process because doing so would make you very spammy. I find it best to read the profiles, find someone I'd like to be connected to, and then connect to them with a custom note.
There are a few caveats in all this that you should be aware of. This is not a perfect system and if the Company Name is not correct, you will get a lot of the same profiles over and over again. DuckDuckGo's search syntax is very simple compared to Google's and the tradeoff is that if your search string is not exact, your results in DuckDuckGo will be very general. However, DuckDuckGo's underlying HTML of its results page is very stable and that allows this script to work. Google, tends to change it randomly so the script will break every single time.
You can write in functionality to log into your LinkedIn account but I wouldn't recommend that. If you rate block yourself on LinkedIn you're SOL (shit out of luck), especially if you do it on your account. So DON'T DO THAT!
Make Candlestick Plots in Python with Plotly
Have you ever wanted to make candlestick charts using Plotly and Python? Are you jealous of these plots and wish you could figure out how to make them? Well today is your lucky day. You can use my Python code below AND your own Alphavantage API key to get stock and technical indicator data to build cool candlestick charts in Python.
Note: My code is a bit hackish and can most definitely be optimized and I export the image to SVG format (you can change that to JPG or PNG). I'm open to suggestions.
#!/usr/bin/env python
# coding: utf-8
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import requests
import datetime as DT
from datetime import datetime
from datetime import date
import sys, os
import time as tt
import plotly.graph_objects as go
#Set Alphavantage API Key
apikey = "XXXXXXXXXXXXXX GET YOUR OWN KEY AND PASTE IT HERE XXXXXXXXXXXXXX"
today = date.today()
#Pass Stock symbol as command line argument
instrument = sys.argv[1]
time = 10
API_URL = "https://www.alphavantage.co/query"
symbol = instrument
data = { "function": "TIME_SERIES_DAILY",
"symbol": symbol,
"outputsize" : "compact",
"datatype": "json",
"apikey": apikey }
response = requests.get(API_URL, data)
response_json_stock = response.json() # maybe redundant
#Manipulate OHLC Frame
data = pd.DataFrame.from_dict(response_json_stock['Time Series (Daily)'], orient= 'index').sort_index(axis=1)
data = data.rename(columns={ '1. open': 'Open', '2. high': 'High', '3. low': 'Low', '4. close': 'Close', '5. volume': 'Volume'})
data = data[['Open', 'High', 'Low', 'Close', 'Volume']]
data['Date'] = data.index
data.tail() # check OK or not
data_50ma = {"function" : "SMA",
"interval" : "daily",
"series_type": "close",
"time_period" : "50",
"symbol": symbol,
"outputsize" : "compact",
"datatype": "json",
"apikey": apikey }
response = requests.get(API_URL, data_50ma)
response_json_50ma = response.json() # maybe redundant
#Manipulate MA Frame
data_50ma = pd.DataFrame.from_dict(response_json_50ma['Technical Analysis: SMA'], orient= 'index').sort_index(axis=1)
data_50ma.columns = ['50DMA']
data_20ma = {"function" : "SMA",
"interval" : "daily",
"series_type": "close",
"time_period" : "20",
"symbol": symbol,
"outputsize" : "compact",
"datatype": "json",
"apikey": apikey }
response = requests.get(API_URL, data_20ma)
response_json_20ma = response.json() # maybe redundant
#Manipulate MA Frame
data_20ma = pd.DataFrame.from_dict(response_json_20ma['Technical Analysis: SMA'], orient= 'index').sort_index(axis=1)
data_20ma.columns = ['20DMA']
df = data['Close']
data['Date'] = pd.to_datetime(data['Date']).dt.date
#Merge data and data_ma
df = data.merge(data_50ma, how='inner', left_index=True, right_index=True)
df = df.merge(data_20ma, how='inner', left_index=True, right_index=True)
fig = go.Figure(data=[go.Candlestick(x=df['Date'],
open=df['Open'],
high=df['High'],
low=df['Low'],
close=df['Close'],
name=symbol),
go.Scatter(x=df['Date'], y=df['50DMA'], line=dict(color='blue', width=1), name="50 DMA"),
go.Scatter(x=df['Date'], y=df['20DMA'], line=dict(color='red', width=1), name="20 DMA")])
fig.update_layout(
title=symbol+ ' Daily Chart',
xaxis_title="Date",
yaxis_title="Price ($)",
font=dict(
family="Courier New, monospace",
size=12,
color="black"
)
)
fig.update_layout(showlegend=True)
fig.write_image("./static/public/2020/" + str(today) + "-" + instrument +".svg")
print ("Successfully generated SVG plot of: ", instrument)
Autogenerating Support and Resistance Lines
Work has been keeping me busy but I found sometime to figure out how to autogenerate support and resistance lines. I cobbled together some code I found online and then made a simple plot. I'm doing this to help me identify the 'zones' in Forex (mostly) and see if I can automate a trading bot to make trades for me.
Here's a chart from two years' worth of daily S&P500 closes. On the surface, the lines look pretty decent but the real trick is figuring out what the right lookback period should be. Here my lookback period was 20 days.
{{< img src="2019_11_05_SP500.png" alt="S&P500 11/05/2019" >}}
There's more work to be done, I have to fix the x-axis to show the dates and get a larger time period. I'm even testing automating this script into some dashboard. Right now you can see a crappy jpg of the EURUSD currency pair on my dev site.
The generic code to build these support and resistance lines is here.
Python Code with Bokeh chart
#!/usr/bin/env python
# coding: utf-8
# In[66]:
#Install Py Package from: https://github.com/hootnot/oanda-api-v20
#https://oanda-api-v20.readthedocs.io/en/latest/oanda-api-v20.html
import json
import oandapyV20
import oandapyV20.endpoints.instruments as instruments
from oandapyV20.contrib.factories import InstrumentsCandlesFactory
#from exampleauth import exampleAuth
import datetime as DT
import pandas as pd
from pandas.io.json import json_normalize
from scipy.signal import savgol_filter as smooth
import matplotlib.pyplot as plt
import numpy as np
# In[67]:
def exampleAuth():
accountID, token = None, None
with open("./oanda_account/account.txt") as I:
accountID = I.read().strip()
with open("./oanda_account/token.txt") as I:
token = I.read().strip()
return accountID, token
# In[68]:
accountID, access_token = exampleAuth()
client = oandapyV20.API(access_token=access_token)
# In[69]:
today = DT.date.today()
two_years_ago = today - DT.timedelta(days=720)
t = today.timetuple()
y = two_years_ago.timetuple()
# In[70]:
#two_years_ago
# In[71]:
instrument = "EUR_USD"
params = {
"from": "2016-01-01T00:00:00Z",
"granularity": "D",
"count": 2000,
}
r = instruments.InstrumentsCandles(instrument=instrument, params=params)
response = client.request(r)
#print("Request: {} #candles received: {}".format(r, len(r.response.get('candles'))))
#print(json.dumps(response, indent=2))
# In[72]:
df = pd.DataFrame(response['candles']).set_index('time')
# In[73]:
df = df['mid']
# In[74]:
time_df = pd.DataFrame(response['candles'])
time = time_df['time']
# In[75]:
df = json_normalize(df).astype(float)
# In[76]:
df = pd.merge(df, time, how='inner', left_index=True, right_index=True)
# In[77]:
df['just_date'] = pd.to_datetime(df['time']).dt.date
# In[78]:
close = df['c']
# In[79]:
data = close.to_numpy()
# In[80]:
#Set Lookback period
time = 20
# In[81]:
def support(ltp, n):
"""
This function takes a numpy array of last traded price
and returns a list of support and resistance levels
respectively. n is the number of entries to be scanned.
"""
# converting n to a nearest even number
if n % 2 != 0:
n += 1
n_ltp = ltp.shape[0]
# smoothening the curve
ltp_s = smooth(ltp, (n + 1), 3)
# taking a simple derivative
ltp_d = np.zeros(n_ltp)
ltp_d[1:] = np.subtract(ltp_s[1:], ltp_s[:-1])
resistance = []
support = []
for i in range(n_ltp - n):
arr_sl = ltp_d[i:(i + n)]
first = arr_sl[:(n // 2)] # first half
last = arr_sl[(n // 2):] # second half
r_1 = np.sum(first > 0)
r_2 = np.sum(last < 0)
s_1 = np.sum(first < 0)
s_2 = np.sum(last > 0)
# local maxima detection
if (r_1 == (n // 2)) and (r_2 == (n // 2)):
resistance.append(ltp[i + ((n // 2) - 1)])
# local minima detection
if (s_1 == (n // 2)) and (s_2 == (n // 2)):
support.append(ltp[i + ((n // 2) - 1)])
return support
# In[82]:
sup = support(data, time)
# In[83]:
df_sup = pd.DataFrame(sup)
# In[84]:
def resistance(ltp, n):
"""
This function takes a numpy array of last traded price
and returns a list of support and resistance levels
respectively. n is the number of entries to be scanned.
"""
# converting n to a nearest even number
if n % 2 != 0:
n += 1
n_ltp = ltp.shape[0]
# smoothening the curve
ltp_s = smooth(ltp, (n + 1), 3)
# taking a simple derivative
ltp_d = np.zeros(n_ltp)
ltp_d[1:] = np.subtract(ltp_s[1:], ltp_s[:-1])
resistance = []
support = []
for i in range(n_ltp - n):
arr_sl = ltp_d[i:(i + n)]
first = arr_sl[:(n // 2)] # first half
last = arr_sl[(n // 2):] # second half
r_1 = np.sum(first > 0)
r_2 = np.sum(last < 0)
s_1 = np.sum(first < 0)
s_2 = np.sum(last > 0)
# local maxima detection
if (r_1 == (n // 2)) and (r_2 == (n // 2)):
resistance.append(ltp[i + ((n // 2) - 1)])
# local minima detection
if (s_1 == (n // 2)) and (s_2 == (n // 2)):
support.append(ltp[i + ((n // 2) - 1)])
return resistance
# In[85]:
res = resistance(data, time)
# In[86]:
df_res = pd.DataFrame(res)
# In[87]:
#start_date = df.just_date.min()
#end_date = df.just_date.max()
#support_line = 1.0800
# In[88]:
from bokeh.plotting import figure, show, output_file
from bokeh.models import Span
from math import pi
# In[89]:
inc = df.c > df.o
dec = df.o > df.c
w = 12*60*60*1000 # half day in ms
TOOLS = "pan,wheel_zoom,box_zoom,reset,save"
# In[90]:
p = figure(x_axis_type="datetime", tools=TOOLS, plot_width=1000, title = instrument + " Currency Pair")
p.xaxis.major_label_orientation = pi/4
p.grid.grid_line_alpha=0.3
# In[91]:
p.segment(df.just_date, df.h, df.just_date, df.l, color="black")
p.vbar(df.just_date[inc], w, df.o[inc], df.c[inc], fill_color="#D5E1DD", line_color="black")
p.vbar(df.just_date[dec], w, df.o[dec], df.c[dec], fill_color="#F2583E", line_color="black")
for i in df_res[0]:
#print (i)
hline_res = Span(location=i, dimension='width', line_color='green', line_width=3)
p.renderers.extend([hline_res])
for i in df_sup[0]:
#print (i)
hline_sup = Span(location=i, dimension='width', line_color='red', line_width=3)
p.renderers.extend([hline_sup])
# In[92]:
output_file('./test.html')
show(p) # open a browser
Changing Pinboard Tags with Python
Welcome to another automation post! This is a super simple Python script for changing misspelled or wrong tags in your Pinboard account. I started using Pinboard again because it helps me save all these great articles I read on the Interwebz, so I can paraphrase and regurgitate them back to you. Ha!
I need to clean out the Pinboard tags every so often because I hooked it up to Twitter. It works well for me because it saves all my retweets, favs and posts, but there's a lot of noise. Sometimes I end up with tags like "DataScience" and "DataScientists" when I really want "DataScience." I did some searching around and found the Pinboard Python library. Changing Pinboard tags with Python is EASY!
What you do need to do is install the Python package for Pinboard and get an API key from your Settings page. Then it's as simple as doing this:
Python Code
import pinboard
pb = pinboard.Pinboard('INSERT_YOUR_API_KEY_HERE')
old_tag = 'DataMining'
new_tag = 'DataScience'
pb.tags.rename(old=old_tag, new=new_tag)
You can, of course modify this script to pass command line arguments to it and just do something like this:
import pinboard
import sys
passcode = str(input('Enter your Pinboard API key here: '))
pb = pinboard.Pinboard(passcode)
old_tag = str(input('Enter the old tag: '))
new_tag = str(input('Enter the new tag: '))
pb.tags.rename(old=old_tag, new=new_tag)
print ('Converted: ' + old_tag+ ' to: ' + new_tag)
Once again, the second script is all open source and free for you to use/modify as you see fit.
Note: I just regurgitated the original script (first one) and then riffed on it for the second one. The Author of Pinboard provided a sample in the documentation. Check that out too!
Automate Feed Extraction and Posting it to Twitter
I wrote a small Python script to automate feed extraction and posting it to Twitter. The feed? My feed burner feed for this site. The script is super simple and uses the Twython Pandas, and Feedparser libraries. The rest, I believe, comes stock with your Python 3 installation.
How it works
It's really a simple process. First it takes a feed, then parses it, does a few things to it, saves it to a CSV file, and text file. Then it opens the text file (not elegant , I know) and randomly selects a row (blog post), and posts it to Twitter. I use this script to compile all my blog posts into a handy link formatted list that I use in my Newsletter.
There are a few things you need to have to run the Twitter part of the script. You'll need to create an API key from Twitter and use your Consumer and Secret tokens to run the Twitter posting.
A lot of this script came from my original one here. I just added in some time filtering procedures. For example:
today = DT.date.today()
week_ago = today - DT.timedelta(days=7)
month_ago = today - DT.timedelta(days=60)
Sets up the time for today, a week ago and a month ago from today's date. I use them to set my time filter in section 4 below and get a list of blog posts posted in the last 7 days or 60 days. You may change these values to your heart's content. The script is open source and free to use anyway you want.
Python Code
# coding: utf-8
# In[1]:
#!/usr/bin/env python
import sys
import os
import random
from twython import Twython, TwythonError
from keys import dict
import datetime as DT
import feedparser
import pandas as pd
import csv
# In[2]:
#Set Time Deltas for tweets
today = DT.date.today()
week_ago = today - DT.timedelta(days=7)
month_ago = today - DT.timedelta(days=60)
t = today.timetuple()
w = week_ago.timetuple()
m = month_ago.timetuple()
# In[3]:
#Parse the Feed
d = feedparser.parse('https://www.neuralmarkettrends.com/feed/')
# In[4]:
#Create List of Feed items and iterate over them.
output_posts = []
for pub_date in d.entries:
date = pub_date.published_parsed
#I need to automate this part below
if date >= m and date <= t:
print (pub_date.title ' : ' pub_date.link)
tmp = pub_date.title,pub_date.link
output_posts.append(tmp)
# In[5]:
#print(output_posts)
#Create Dataframe for easy saving later
df = pd.DataFrame(output_posts, columns = ["Title", "RawLink"])
# In[6]:
date_f = str(DT.date.today())
#f = open (date_f '-posts.md', 'w')
f = open ('60daytweet.txt', 'w')
for t in output_posts:
line = ' : '.join(str(x) for x in t)
f.write(line '\n')
f.close()
# In[7]:
#Create Preformated link to export to CSV
df['Hyperlink'] = '<a href="' df['RawLink'] '">' df['Title'] '</a>'
# In[8]:
#Write to CSV for Newsletter
df.to_csv("formated_link_list.csv", quoting=csv.QUOTE_NONE)
# In[9]:
#Initialize automatic Twitter posting of random blog article
#Add your Twitter API keys by replacing 'dict['ckey|csecret|atoken|asecret'] with the applicable values like so 'XXXXXX'
CONSUMER_KEY = dict['ckey']
CONSUMER_SECRET = dict['csecret']
ACCESS_KEY = dict['atoken']
ACCESS_SECRET = dict['asecret']
f = open('60daytweet.txt', 'r')
lines = f.readlines()
f.close()
post = random.choice(lines)
api = Twython(CONSUMER_KEY,CONSUMER_SECRET,ACCESS_KEY,ACCESS_SECRET)
try:
api.update_status(status=post)
except TwythonError as e:
print (e)
Extract Blog Links from RSS with Python
As part of my goal of automation here, I wrote a small script to extract blog post links from RSS feeds. using Python. I did this to extract the title and link of blog posts from a particular date range in my RSS feed. In theory, it should be pretty easy but I've come to find that time was not my friend.
What tripped me up was how some functions in python handle time objects. Read on to learn more!
What it does
What this script does is first scrape my RSS feed, then use a 7 day date range to extract the posted blog titles and links, and then writes it to a markdown file. Super simple, and you'll need the feedparser library installed.
The real trick her is not the loop, but the timetuple(). This is where I first got tripped up.
I first created a variable for today's date and another variable for 7 days before, like so:
import datetime as DT
import feedparser
today = DT.date.today()
week_ago = today - DT.timedelta(days=7)
The output of today becomes this: datetime.date(2018, 9, 8)
The output of week_ago becomes this: datetime.date(2018, 9, 1)
So far so good! The idea was to use a logic function like if post.date >= week_ago AND post.date <= today, then extract stuff.
So I parsed my feed and then using the built in time parsing features of feedparser, I wrote my logic function.
BOOM, it didn't work. After sleuthing the problem I found that the dates extracted in feedparser were a timestruct object whereas my variables today and week_ago were datetime objects.
Enter timetuple() to the rescue. timetuple() changed the datetime object into a timestruct object by just doing this:
t = today.timetuple()
w = week_ago.timetuple()
#Straightforward to do the loop and write out the results, see below.
## Python Script
import datetime as DT
import feedparser
today = DT.date.today()
week_ago = today - DT.timedelta(days=7)
#Structure the times so feedparser and datetime can talk
t = today.timetuple()
w = week_ago.timetuple()
#Parse THE FEED!
d = feedparser.parse('https://www.neuralmarkettrends.com/feeds/all.atom.xml')
#Create list to write extract posts into
output_posts = []
for pub_date in d.entries:
date = pub_date.published_parsed
#I need to automate this part below
if date >= w and date <= t:
tmp = pub_date.title,pub_date.link
output_posts.append(tmp)
print(output_posts)
#Write to File
date_f = str(DT.date.today())
f = open (date_f + '-posts.md', 'w')
for t in output_posts:
line = ' : '.join(str(x) for x in t)
f.write(line + 'n')
f.close()
Parsing Blog Feeds with Python
I'm going to share an update to my original python script. It's super simple and it completely automates parsing multiple blog feeds for you to autopost on Twitter.
The goal: automation!!!
Call the Python Modules
Create a new empty python script. Call it awesomescript.py or something else. You'll need to have feedparser and twython installed first. If you don't go and do 'pip install feedparser' and 'pip install Twython.'
import feedparser
import sys
import os
import random
from twython import Twython, TwythonError
from keys import dict
The one thing you'll notice is I'm calling a python file called 'keys' and importing a dictionary. All that this does is call my Twitter API keys from one central file. I do this because I have multiple scripts that call the same keys and instead of pasting them in each an every script, I just centralized it. Plus, it makes it easier to change the keys if I ever rate block myself, which is a fairly common occurrence with all my tinkering!
Twitter API Key dictionary
Ok, you need to get your API keys from Twitter. Do that first. Google how to do it. Then create a file called 'keys.py' and paste the following into it. Then paste in your Consumer Key, Consumer Secrete, Access Token, and Access Secret into where the 'XXXXXXXXXXXXXXX's are.
dict = {'ckey': 'XXXXXXXXXXXXXXX', 'csecret': 'XXXXXXXXXXXXXXX', 'atoken': 'XXXXXXXXXXXXXXX', 'asecret':'XXXXXXXXXXXXXXX}'
Calling the Dictonary of keys
Switch back to your main script and call in the key.py file by doing this:
CONSUMER_KEY = dict['ckey']
CONSUMER_SECRET = dict['csecret']
ACCESS_KEY = dict['atoken']
ACCESS_SECRET = dict['asecret']
Create the Feedlist you want to parse the RSS feed from
You'll have to create a list of RSS feeds from where you want to parse the posts from. To do that you need to create a list in Python by doing something like 'myvariable = []'
feedlist = ['https://www.someurl.com/feed',
'https://www.someurl2.com/feed',
'https://www.someurl3.com/feed',
'https://www.someurl4.com/feed',
'https://www.someurl5.com/feed']
Make a Random Feed Selection and Parse the Feed
Next we're going to randomly select a feed and then parse it via the feedparser library.
select_list = random.choice(feedlist)
d = feedparser.parse(select_list)
Extract the feed length and randomly select a Feed
This part is where I made the biggest change. I now parse the number of feeds and then automatically assign that number to a variable. This way I can create the correct feed range 'on the fly' because each feed is different. Some sites only give you 5 current feeds, others give you 20, etc. In my old feed, I just hard coded in a range value. That worked but wasn't very dynamic.
feedlen = len(d['entries'])
num = random.randint(0,feedlen)
Initialize Twitter API, Write the Status and Tweet Out
The rest didn't change much at all. You just initialize the Twitter API and write a status that appends the parsed feed information.
api = Twython(CONSUMER_KEY,CONSUMER_SECRET,ACCESS_KEY,ACCESS_SECRET)
status_text = d['entries'][num]['title'] + ' link: '+ d['entries'][num]['link']
try:
api.update_status(status=status_text)
except TwythonError as e:
print (e)
There you have it. A better version of my original script. The next goal is create a list of hashtags to randomly select against.
As always, please drop me a comment if you have questions.
Keras and NLTK
I've been doing a lot more Python hacking, especially around text mining and using the deep learning library Keras and NLTK. Normally I'd do most of my work in RapidMiner but I wanted to do some grunt work and learn something along the way. It was really about educating myself on Recurrent Neural Networks (RNN) and doing it the hard way I guess.
As usually I went to google to do some sleuthing about how to text mine using an LSTM implementation of Keras and boy did I find some goodies. The best tutorials are easy to understand and follow along. My introduction to Deep Learning with Keras was via Jason's excellent tutorial called Text Generation with LSTM Recurrent Neural Networks in Python with Keras. Jason took a every easy to bite approach to implementing Keras to read in the Alice In Wonderland book character by character and then try to generate some text in the 'style' of what was written before. It was a great Proof of Concept but fraught with some strange results. He acknowledges that and offers some additional guidance at the end of the tutorial, mainly removing punctuation and more training epochs. The text processing is one thing but the model optimization is another. Since I have a crappy laptop I can just forget about optimizing a Keras script, so I went the text process route and used NLTK. Now that I've been around the text mining/processing block a bunch of times, the NLTK python library makes more sense in this application. I much prefer using the RapidMiner Text Processing implementation for 90% of what I do with text but every so often you need something special and atypical.
Initial Results
The first results were terrible as my tweet can attest too!
{{< tweet user="thomasottio" id="895711890457804800" >}}
So I added a short function to Jason's script that preprocesses a new file loaded with haikus. I removed all punctuation and stop words with the express goal of generating haiku. While this script was learning I started to dig around the Internet for some other interesting and related posts on LSTM's, NLTK and text generation until I found Click-O-Tron. That cracked me up. Leave it to us humans to take some cool piece of technology and implement it for lulz.
Implementation
I have grandiose dreams of using this script so I would need to put it in production one day. This is where everything got to be a pain in the ass. My first thought was to run the training on a smaller machine and then use the trained weights to autogenerate new haikus in a separate scripts. This is not an atypical type of implementation. Right now I don't care if this will take days to train. While Python is great in many ways, dealing with libraries on one machine might be different on another machine and hardware. Especially when dealing with GPU's and stuff like that. It's gets tricky and annoying considering I work on many different workstations these days. I have a crappy little ACER laptop that I use to cron python scripts for my Twitter related work, which also happens to be an AMD processor. I do most of my 'hacking' on larger laptop that happens to have an Intel processor. To transfer my scripts from one machine to another I have to always make sure that every single Python package is installed on each machine. PITA! Despite these annoyances, I ended up learning A LOT about Deep Learning architecture, their application, and short comings. In the end, it's another tool in a Data Science toolkit, just don't expect it to be a miracle savior.
Additional reading list
- https://h6o6.com/2013/03/using-python-and-the-nltk-to-find-haikus-in-the-public-twitter-stream/
- https://github.com/fchollet/keras/blob/master/examples/lstm_text_generation.py
The Python Script
#https://machinelearningmastery.com/text-generation-lstm-recurrent-neural-networks-python-keras/
import numpy
import os
import sys
import nltk
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import LSTM
from keras.callbacks import ModelCheckpoint
from keras.utils import np_utils
import string
from nltk.tokenize import RegexpTokenizer
from nltk.corpus import stopwords
import re
# look at https://gist.github.com/ameyavilankar/10347201#file-preprocess-py-L1
def preprocess(sentence):
sentence = sentence.lower()
tokenizer = RegexpTokenizer(r'\w+')
tokens = tokenizer.tokenize(sentence)
filtered_words = filter(lambda token: token not in stopwords.words('english'), tokens)
return " ".join(filtered_words)
# load ascii text and covert to lowercase
filename = "haikus.txt"
sentence = open(filename).read()
#raw_text = raw_text.lower()
#raw_text = nltk.sent_tokenize(raw_text)
sentence = preprocess(sentence)
#print (sentence)
raw_text = sentence
#print (raw_text)
# create mapping of unique chars to integers
chars = sorted(list(set(raw_text)))
#print (chars)
char_to_int = dict((c, i) for i, c in enumerate(chars))
#print (char_to_int)
n_chars = len(raw_text)
n_vocab = len(chars)
print ("Total Characters: ", n_chars)
print ("Total Vocab: ", n_vocab)
# prepare the dataset of input to output pairs encoded as integers
seq_length = 300
dataX = []
dataY = []
for i in range(0, n_chars - seq_length, 1):
seq_in = raw_text[i:i + seq_length]
seq_out = raw_text[i + seq_length]
dataX.append([char_to_int[char] for char in seq_in])
dataY.append(char_to_int[seq_out])
n_patterns = len(dataX)
print ("Total Patterns: ", n_patterns)
# reshape X to be [samples, time steps, features]
X = numpy.reshape(dataX, (n_patterns, seq_length, 1))
# normalize
X = X / float(n_vocab)
# one hot encode the output variable
y = np_utils.to_categorical(dataY)
# define the LSTM model
model = Sequential()
model.add(LSTM(256, input_shape=(X.shape[1], X.shape[2]), return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(256))
model.add(Dropout(0.2))
model.add(Dense(y.shape[1], activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam')
# define the checkpoint
filepath="weights-improvement-{epoch:02d}-{loss:.4f}.hdf5"
checkpoint = ModelCheckpoint(filepath, monitor='loss', verbose=1, save_best_only=True, mode='min')
callbacks_list = [checkpoint]
model.fit(X, y, epochs=3, batch_size=256, callbacks=callbacks_list)
Parse Blog Feeds with Python (1st version)
I recently wrote a small a python script to parse blog feeds and then
tweet them out via Twitter. It randomly takes the first 5 RSS entries of
a feed and them tweets one out. You'll need to get an API
key from Twitter and the
credentials, but it's a neat way to keep your readers updated of the
various feeds you read or write. Just replace the
'XXXXXXXXXXXXXXXXXXXXXX' with the various keys you get from Twitter.
import feedparser
import sys
import os
import random
from twython import Twython, TwythonError
CONSUMER_KEY = 'XXXXXXXXXXXXXXXXXXXXXX'
CONSUMER_SECRET = 'XXXXXXXXXXXXXXXXXXXXXX'
ACCESS_KEY = 'XXXXXXXXXXXXXXXXXXXXXX'
ACCESS_SECRET = 'XXXXXXXXXXXXXXXXXXXXXX'
num = random.randint(0,5)
d = feedparser.parse('https://www.neuralmarkettrends.com/feed')
api = Twython(CONSUMER_KEY,CONSUMER_SECRET,ACCESS_KEY,ACCESS_SECRET)
status_text = 'Fresh: ' + d['entries'][num]['title'] + ' link: '+ d['entries'][num]['link'] + ' #NMT'
try:
api.update_status(status=status_text)
except TwythonError as e:
print (e)
A simple Blog Post Tweeter in Python
I continue on my journey to rebuild this blog's traffic. One idea I had was to build a simple Python based blog post tweeter. I would select a blog post at random and then tweet it to my @neuralmarket Twitter account. I chose Python because of the Twython package. It made for a simple connection to my Twitter account and was easy to parse a text file.
The idea was this. I create a text file of all the blog posts I want to retweet - appended with a bit.ly link - and write a catchy tweet. I would then run the Python script to select at random a pre-written tweet from the text file. When I'm ready, I can cron job this script and run it once or twice a day. Over time I can add or delete pre-written tweets or try to optimize them for SEO.
I suggest that all my readers try this, it's not hard and is simple to follow.
The Twitter Token
First you have to get a Twitter token. This allows you the Python script to post on your behalf and there are four bits of information you need. First visit dev.twitter.com and navigate to the application owner access token page. There you can learn on how to make a single application and generate the follow api values:
Consumer Key
Consumer Secret
Access Token
Access Token Secret
You'll need these four items for the Python script below.
The text file
Next, create a simple text file (TXT extension) and put a single tweet per line. Make sure to add your blog post link. I use bit.ly to shorten my long URLs.
Here's an example of my text file:
Autogenerate Blog Posts with .@Rapidminer https://bit.ly/1RRb0Hd
A simple Stock Trend Following model in .@Rapidminer https://bit.ly/1UjDta0
What does Value really mean? For reals! https://bit.ly/1Y4PaaK
What to expect from being a Sales Engineer at a Startup https://bit.ly/1Y4PR3A
Make sure to save this file in the same directory as your Python script. I keep all my scripts and files in a Dropbox folder so I can access it anywhere.
The Code
Now here's the code. I'm going to "XXX" out my consumer and access keys, you'll have to add your own from the first step above.
#!/usr/bin/env python
import sys
import os
import random
from twython import Twython, TwythonError
CONSUMER_KEY = 'XXXXXXXXXXXXXXXXXXXXXX'
CONSUMER_SECRET = 'XXXXXXXXXXXXXXXXXXXXXX'
ACCESS_KEY = 'XXXXXXXXXXXXXXXXXXXXXX'
ACCESS_SECRET = 'XXXXXXXXXXXXXXXXXXXXXX'
#Use the following path structure for linux machine
#f = open('/home/path/to/tweet.txt', 'r')
#Use the following path structure for a windows machine
f = open('C:\\path\\to\\tweet.txt', 'r')
lines = f.readlines()
f.close()
post = random.choice(lines)
api = Twython(CONSUMER_KEY,CONSUMER_SECRET,ACCESS_KEY,ACCESS_SECRET)
try:
api.update_status(status="R2D2 says: " + post)
except TwythonError as e:
print e





Member discussion